简介
OpenResty对于进程间的通讯,提供了共享内存的机制,也就是名为ngx.shared的方法。
我们会基于它去进行封装,更多的应用场景也是用于缓存。
缓存有两个原则
一是越靠近用户的请求越好,比如能用本地缓存的就不要发送HTTP请求,能用CDN缓存的就不要打到web服务器,能用nginx缓存的就不要用数据库的缓存。
二是尽量使用本进程和本机的缓存解决,因为跨了进程和机器甚至机房,缓存的网络开销就会非常大,在高并发的时候会非常明显。
根据以上原则,会优先使用进程内的缓存,OpenResty提供了一个进程缓存模块lua-resty-lrucache,会把共享内存作为二级缓存。
缓存模块
通常情况,我们会用成熟的组件lua-resty-mlcache做多级缓存,它提供了三级缓存机制。
它的架构如下:
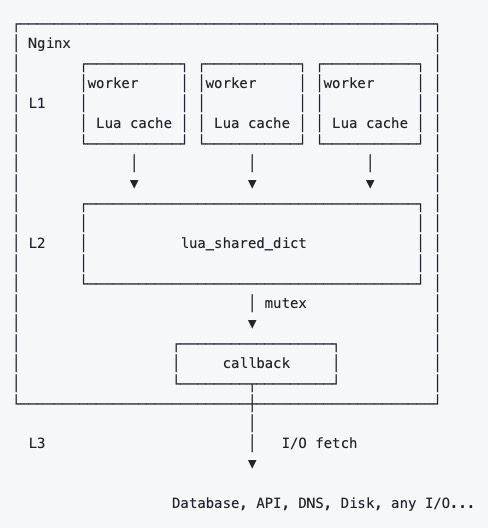
我们直接贴一下官方的示例
# nginx.conf
http {
lua_package_path "/path/to/lua-resty-mlcache/lib/?.lua;;";
lua_shared_dict cache_dict 1m;
init_by_lua_block {
local mlcache = require "resty.mlcache"
local cache, err = mlcache.new("my_cache", "cache_dict", {
lru_size = 500, -- size of the L1 (Lua VM) cache
ttl = 3600, -- 1h ttl for hits
neg_ttl = 30, -- 30s ttl for misses
})
if err then
end
_G.cache = cache
}
server {
listen 8080;
location / {
content_by_lua_block {
local function callback(username)
return db:get_user(username) -- { name = "John Doe", email = "[email protected]" }
end
local user, err = cache:get("my_key", nil, callback, "John Doe")
ngx.say(user.username) -- "John Doe"
}
}
}
}
以上的示例很好了描述了整个程序运行的逻辑,在init阶段初始化缓存,然后用_G变量赋予全局变量,在使用阶段cache:get获取指定Key的缓存,缓存未命中就会调用L3,也就是callback方法。
缓存失效风暴
但这个示例中缺失了lua-resty-lock这个组件的调用。
通常在L3阶段都是查询外部的数据库,如果在缓存失效的一瞬间,一万个并发请求同时到达,那么将会产生一万次数据查询,事实上我们只需要查询一次即可。
为了防止在L3阶段发生这种情况(缓存失效风暴),所以利用好锁的机制非常重要。
我们将局部配置修改如下:
lua_shared_dict cache_dict 1m;
lua_shared_dict cache_lock 1m;
init_by_lua_block {
local mlcache = require "resty.mlcache"
local cache, err = mlcache.new("my_cache", "cache_dict", {
lru_size = 500, -- size of the L1 (Lua VM) cache
ttl = 3600, -- 1h ttl for hits
neg_ttl = 30, -- 30s ttl for misses
shm_locks = "cache_lock",
resty_lock_opts = {
exptime = 10,
timeout = 5
}
})
if err then
end
}
进程之间数据同步
这个问题我们使用lua-resty-worker-events模块解决。
此模块提供了一种向Nginx服务器中的其他工作进程发送事件的方法。通信是通过一个共享的存储区进行的,事件数据将存储在该存储区中。
结合我们之前的缓存使用场景,在一个Worker中的缓存更新之后,要通知其他Worker也同步更新,它就发挥作用了。
我们看以下官方提供的示例
lua_shared_dict process_events 1m;
init_worker_by_lua_block {
local ev = require "resty.worker.events"
local handler = function(data, event, source, pid)
print("received event; source=",source,
", event=",event,
", data=", tostring(data),
", from process ",pid)
end
ev.register(handler)
local ok, err = ev.configure {
shm = "process_events", -- defined by "lua_shared_dict"
timeout = 2, -- life time of unique event data in shm
interval = 1, -- poll interval (seconds)
wait_interval = 0.010, -- wait before retry fetching event data
wait_max = 0.5, -- max wait time before discarding event
shm_retries = 999, -- retries for shm fragmentation (no memory)
}
if not ok then
ngx.log(ngx.ERR, "failed to start event system: ", err)
return
end
}
在init_worker_by_lua_block阶段初始化,是因为它需要在每个Worker中都运行,便于同步到其他进程,其他的就是一些配置参数问题。
下面我们把它结合上面的缓存模块一起使用。
lua-resty-mlcache提供了ipc接口来支持lua-resty-worker-events模块,我们直接配置参数即可。
lua_shared_dict cache_dict 1m;
lua_shared_dict cache_lock 1m;
lua_shared_dict worker_events 1m;
init_worker_by_lua_block {
local mlcache = require "resty.mlcache"
local worker_events = require "resty.worker.events"
local ok, err = worker_events.configure {
shm = "worker_events",
timeout = 2,
interval = 1,
wait_interval = 0.010,
wait_max = 0.5,
shm_retries = 999,
}
local cache, err = mlcache.new("my_cache", "cache_dict", {
lru_size = 500, -- size of the L1 (Lua VM) cache
ttl = 3600, -- 1h ttl for hits
neg_ttl = 30, -- 30s ttl for misses
shm_locks = "cache_lock",
resty_lock_opts = {
exptime = 10,
timeout = 5
},
ipc = {
register_listeners = function(events)
for _, event_t in pairs(events) do
worker_events.register(
function(data)
event_t.handler(data)
end,
channel_name,
event_t.channel
)
end
end,
broadcast = function(channel, data)
worker_events.post(channel_name, channel, data)
end
}
})
if err then
end
}
以上ipc部分代码截取自Kong项目,有兴趣也可以去参考一下它的设计模式。